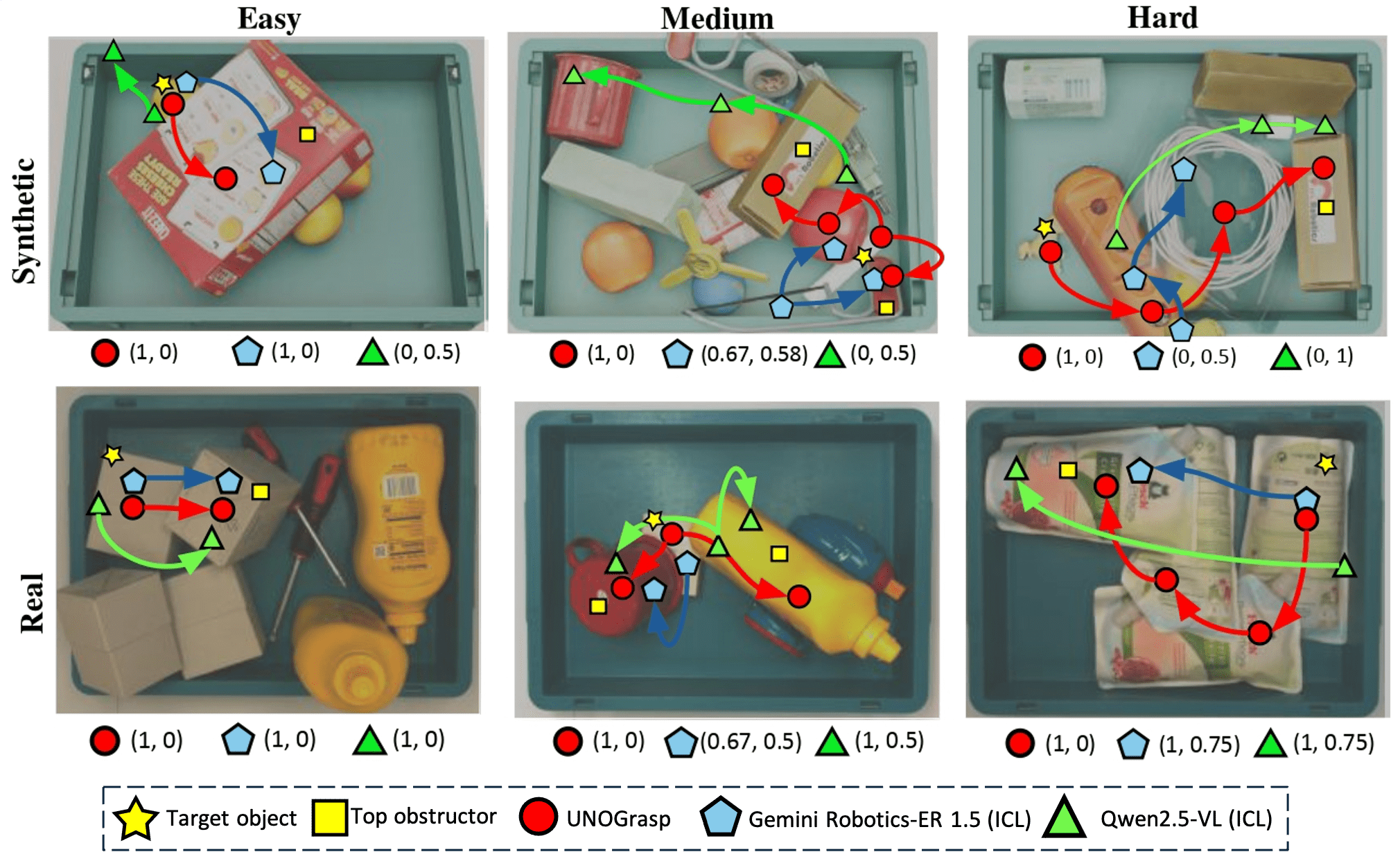
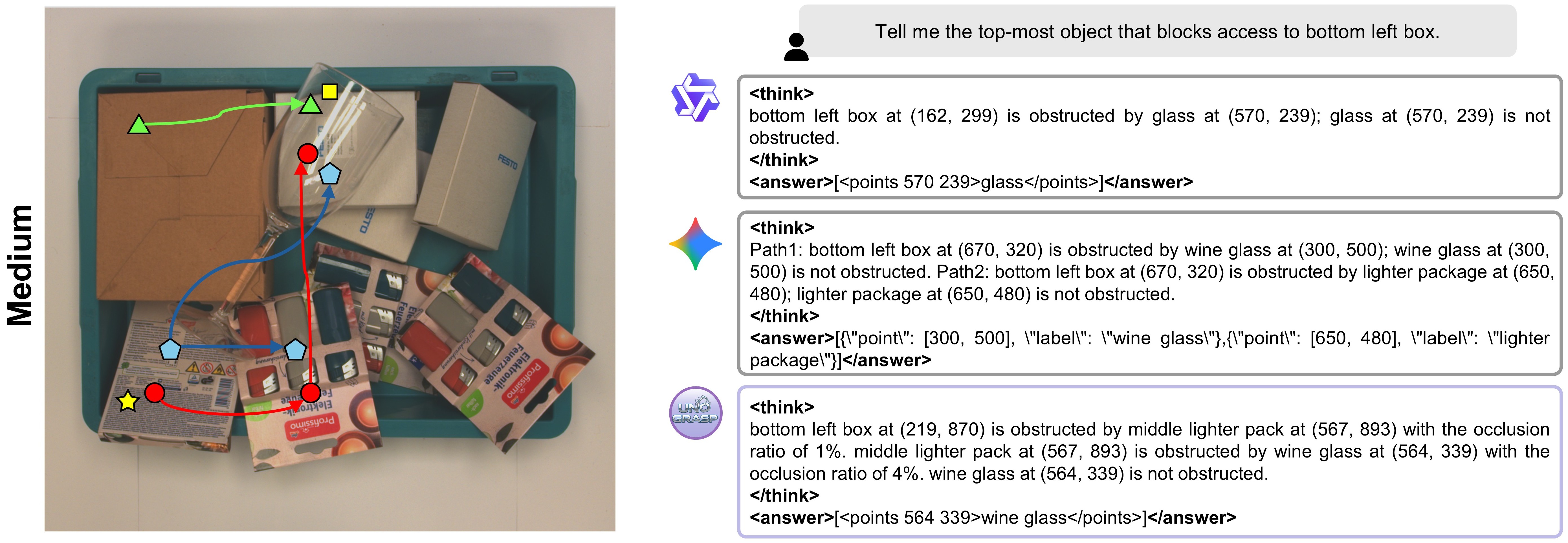
Successful robotic grasping in cluttered environments not only requires a model to visually ground a target object but also to reason about obstructions that must be cleared beforehand. While current vision-language embodied reasoning models show emergent spatial understanding, they remain limited in terms of obstruction reasoning and accessibility planning. To bridge this gap, we present UNOGrasp, a learning-based vision-language model capable of performing visually-grounded obstruction reasoning to infer the sequence of actions needed to unobstruct the path and grasp the target object. We devise a novel multi-step reasoning process based on obstruction paths originated by the target object. We anchor each reasoning step with obstruction-aware visual cues to incentivize reasoning capability. UNOGrasp combines supervised and reinforcement finetuning through verifiable reasoning rewards. Moreover, we construct UNOBench, a large-scale dataset for both training and benchmarking, based on MetaGraspNetV2, with over 100k obstruction paths annotated by humans with obstruction ratios, contact points, and natural-language instructions. Extensive experiments and real-robot evaluations show that UNOGrasp significantly improves obstruction reasoning and grasp success across both synthetic and real-world environments, outperforming generalist and proprietary alternatives.

UNOBench features two unique characteristics: (i) human-annotated free-form language instructions about objects in cluttered bins, and (ii) per-bin obstruction graphs for grounded spatial reasoning. Human annotators through the Prolific platform were involved to refine the initial GPT-4o generated annotations. UNOBench features three levels of difficulty and introduces novel evaluation metrics.













@misc{jiao2025obstruction,
author = {Runyu Jiao and Matteo Bortolon and Francesco Giuliari and Alice Fasoli and Sergio Povoli and Guofeng Mei and Yiming Wang and Fabio Poiesi},
title = {Obstruction reasoning for robotic grasping},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
year = {2026}
}

